

Ideas, información y conocimientos compartidos por el equipo
de Investigación, Desarrollo e Innovación de BASE4 Security.
Ideas, información y conocimientos compartidos por el equipo
de Investigación, Desarrollo e Innovación de BASE4 Security.

POR:
Felipe Alves
CYBER SECURITY RESEARCHER & TRAINER
COMPARTIR
REFERENCIAS
B. Claise, B. Trammell, and P. Aitken, “Specification of the IP Flow Information
Export (IPFIX) Protocol for the Exchange of Flow Information,” RFC 7011 (Internet
Standard), Internet Engineering Task Force, September 2013. [Online]. Available: http://www.ietf.org/rfc/rfc7011.txt
What is NetFlow? An Overview of the NetFlow Protocol. Disponível em: https://www.kentik.com/kentipedia...
¿Por qué utilizar datos de flujo para el monitoreo?
En el punto en el que nos encontramos en la curva creciente de la
evolución tecnológica y, en consecuencia, de las amenazas digitales, crece con la misma
intensidad la necesidad de visibilidad en relación con los datos que atraviesan las
infraestructuras de diversos tipos de organizaciones. La demanda de esta visibilidad puede
tropezar con varios aspectos técnicos, que van desde la necesidad de buenas estrategias de
posicionamiento de los equipos de captura hasta la necesidad de grandes cantidades de
hardware para el almacenamiento y procesamiento de los datos capturados. Otro punto al que
hay que prestar atención es el valor que tienen los datos capturados, es decir, es
importante saber si lo que se está almacenando aporta realmente la visibilidad y la
capacidad de supervisión deseadas.
A partir de estas ideas, surgen naturalmente algunas preguntas, y en los círculos de debate
de los Blue Teamers, las preguntas que siempre están presentes son: ¿qué debo captar?
¿Capturar todo el tráfico durante menos tiempo (debido a las limitaciones del hardware)?
¿Capturar sólo los metadatos y realizar correlaciones con los registros disponibles?. Un
buen tópico que respondería estas preguntas sería: hay que trabajar con equilibrio, porque
ambos enfoques aportan visibilidad y tienen ventajas e inconvenientes.
En un principio se puede pensar que el escenario ideal es tener el tráfico completamente
capturado para dar soporte a las actividades de respuesta a incidentes, caza de amenazas,
SOC, CSIRT, etc., ya que a través de la captura completa es posible reconstruir la
comunicación entre cliente y servidor y tener una visión real de lo sucedido, pero, aunque
esto pueda parecer realmente el mejor de los mundos para las investigaciones, el histórico
disponible no irá más allá de unos pocos días o semanas, debido a la gran cantidad de
recursos necesarios. Esto se convierte en un problema cuando necesitamos investigar algo que
ocurrió en un periodo anterior a la capacidad histórica, sin tener en cuenta los problemas
que pueden surgir al tratar con tráfico cifrado. Una alternativa equilibrada es obtener
metadatos de este tráfico integrados con logs, que pueden cubrir buena parte de la
organización en cuanto a estadísticas sobre las conexiones realizadas entre usuarios de la
infraestructura.
En este contexto, el objetivo de este artículo es discutir la segunda opción mencionada en
el párrafo anterior, que es un enfoque interesante para la captura completa del tráfico y es
capaz de ofrecer una buena visibilidad sobre temas como: quién se comunica con quién, cuándo
se produjo esta comunicación, durante cuánto tiempo y con qué frecuencia. Se trata de
capturar flujos de datos, exportarlos y crear métricas de monitorización basadas en esos
flujos, a través de protocolos como el que Cisco denominó originalmente NetFlow, y que
posteriormente fue "traducido" a una versión opensource que se denominó IPFIX. Este tipo de
enfoque puede ser muy beneficioso para la supervisión continua de una organización, ya que
permite mantener una trazabilidad histórica mucho mayor de las comunicaciones, simplemente
porque requiere menos recursos de almacenamiento en comparación con la captura completa del
tráfico.
Este es el primero de una serie de 2 posts sobre este tema. En él definiremos algunos
conceptos y reflexionaremos sobre estrategias de vigilancia y, en otro momento, abordaremos
herramientas, técnicas y demostraciones prácticas.
¿Qué es Netflow/Dataflow/Flow?
Buscando la información directamente de la fuente, el RFC 7011 de 2013 que especifica el
protocolo IPFIX, define el flujo de datos, o simplemente flujo, como lo siguiente: "un
conjunto de paquetes IP que pasan a través de un punto de observación dentro de la red
durante un cierto intervalo de tiempo, teniendo todos los paquetes pertenecientes a un flujo
particular un conjunto de propiedades en común."
Las propiedades de los flujos, también llamadas flow-keys son cada uno de los campos que:
(i) pertenecen a la propia cabecera del paquete; (ii) son propiedades del paquete, como el
tamaño en bytes; (iii) se derivan de la actividad de Manejo de Paquetes, como el Número de
Sistema Autónomo (ASN).
En resumen, cada flujo es un conjunto de paquetes agregados, es decir, los paquetes no se
consideran individualmente, como en un enfoque de captura completa. Es como si las
secuencias de paquetes tuvieran una especie de firma que se utiliza para unir los distintos
elementos de una comunicación en un único flujo. Los flujos contienen valiosos metadatos
sobre las comunicaciones y deben ser exportados por algún equipo por el que pasa el tráfico,
denominado "exportador" (normalmente cortafuegos, conmutadores y enrutadores), y recopilados
para su posterior análisis.
También de acuerdo con la RFC, la recopilación de este flujo sirve tanto como para fines
administrativos como para cualquier otro, como los mencionados al principio de esta
publicación, por ejemplo: la visibilidad, pero también la resolución de problemas, la
detección de amenazas, la supervisión del rendimiento y, en consecuencia, ¡la Seguridad!
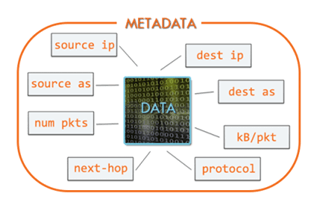
Metadatos
Como se ha mencionado anteriormente, un exportador de flujos identifica un flujo como un
conjunto de paquetes con características comunes pertenecientes a una comunicación
determinada. Estas características contenidas en los paquetes son al menos: puerto de la
interfaz de entrada, direcciones IP de origen y destino, puertos de origen y destino,
protocolo y tipo de servicio. Curiosamente, estos también pueden considerarse como los
principales atributos de la comunicación que serán útiles para análisis posteriores,
recordando siempre que se trata de metadatos, es decir: el contenido de los paquetes no está
disponible. Hablaremos de ello más adelante.
Exportar
Los procesos de captura y análisis de flujos dependen básicamente de 3 componentes: un
equipo "exportador"; un equipo "recolector"; y, por último, un equipo/software analizador de
flujos.
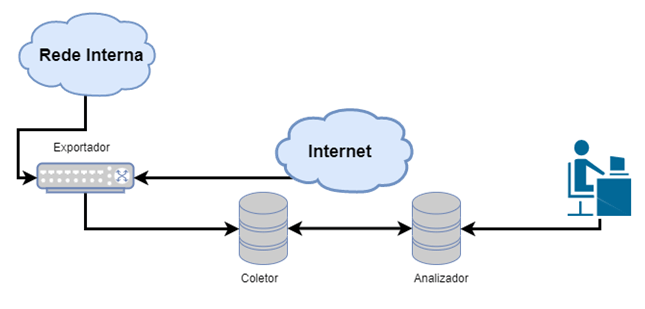
Un flujo se exporta cuando cumple ciertos requisitos: (i) el flujo se vuelve inactivo, es
decir, no se recibe ningún paquete nuevo relacionado con este flujo hasta que alcanza el
tiempo de espera (que es configurable); (ii) el flujo sigue procesando paquetes, pero
alcanza el tiempo de espera establecido; (iii) algo en la comunicación indica que se ha
terminado, por ejemplo, banderas TCP de tipo FIN o RST.
Después, los flujos se transmiten al colector, que suele ser un equipo centralizador de
varios exportadores. Esta transmisión se realiza normalmente a través de UDP, pero los
equipos más modernos son capaces de transmitir a través de TCP para añadir cierto control,
lo que puede traer algún impacto en relación con el rendimiento del dispositivo.
El recopilador también almacena estos flujos para su posterior análisis mediante software,
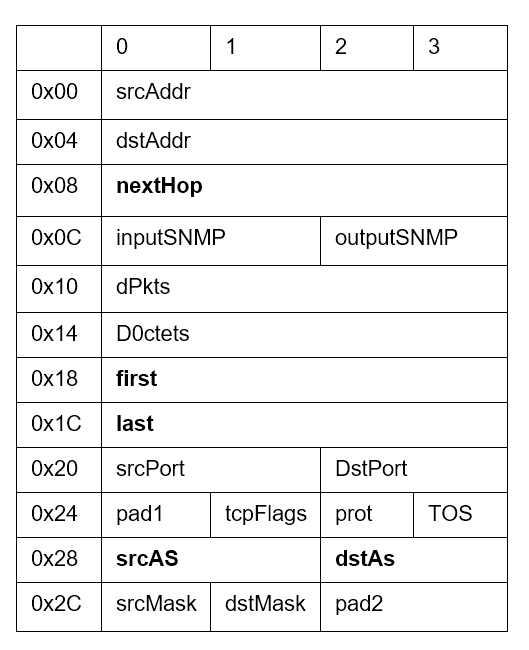
analizador dedicado, SIEM, etc. Al final de la exportación, lo que tenemos que analizar son
los conjuntos de metadatos de la comunicación, que suelen incluir: direcciones y puertos de
origen y destino (cuando se trata de comunicaciones TCP o UDP), tipo de servicio, marcas de
tiempo de inicio y fin de la comunicación, información sobre las interfaces de entrada y
salida del dispositivo, banderas TCP y protocolo encapsulado (tipo de datos que se
transmiten, si son TCP o UDP), información sobre protocolos de enrutamiento como BGP
(siguiente salto, AS de origen, AS de destino...). La siguiente tabla muestra los campos
presentes en la cabecera del protocolo netflow V5.
¿Por qué son útiles los datos de flujo?
Los datos de flujo son un aliado importante porque muestran, a bajo coste, un resumen
estadístico de las comunicaciones que pasan por los exportadores. Por eso es necesaria una
buena estrategia para elegir buenas posiciones de exportación, es decir, seleccionar los
equipos con mayor potencial de visibilidad (cortafuegos, conmutadores, routers). Dependiendo
de la herramienta elegida para realizar el análisis, (y hay varias, tanto de código abierto
como comerciales) es posible ver cosas como
• Estadísticas de tráfico divididas por aplicación; protocolo; dominio;
IP de origen y destino y puerto;
• Resumen estadístico (Top N) de direcciones, comunicaciones e incluso
Sistemas Autónomos (AS);
• Resumen estadístico de la información descrita anteriormente con
enriquecimiento por herramientas de análisis de flujo¸ o por SIEM, como Geolocalización y
otras
Este tipo de información ayuda a comprender cuestiones sobre la infraestructura de la
organización. Es posible averiguar si se están ejecutando aplicaciones prohibidas; encontrar
cuellos de botella o equipos que funcionan mal; descubrir anomalías de consumo excesivo o
exagerado de ancho de banda por parte de algunos equipos; entender conexiones extrañas a
direcciones de países con altos índices de ciberataques, así como AS con mala reputación;
comunicación con servidores de comando y control, entre otras cosas.
De nuevo: los datos de flujo no agregan el contenido de las comunicaciones. Teniendo esto en
cuenta, un analista que sólo disponga de esta información deberá asociar siempre algunos
factores para obtener inteligencia a partir de este tipo de metadatos. La misma observación
se aplica a los datos cifrados, incluso cuando el tráfico se captura por completo. Esta
asociación de factores puede hacerse pensando:
1. Sobre la direccionalidad del tráfico - saber cuál debe ser la
dirección típica de la conversación entre cliente y servidor, por ejemplo: ¿es legítimo que
un servidor X en la red DMZ acceda a cualquier servicio en Internet en el puerto 1234?
2. Sobre el tráfico esperado asociado al protocolo implicado en la
comunicación - conociendo bien cómo funcionan determinados protocolos, es posible hacerse
una idea de si el tráfico debería tener una duración mayor o menor, una cantidad de datos
mayor o menor, y a partir de ahí encontrar anomalías;
3. En el análisis basado en el tiempo: para identificar picos de
tráfico que puedan indicar transferencias de archivos, o comunicaciones extrañas que puedan
referirse a respuestas a comandos;
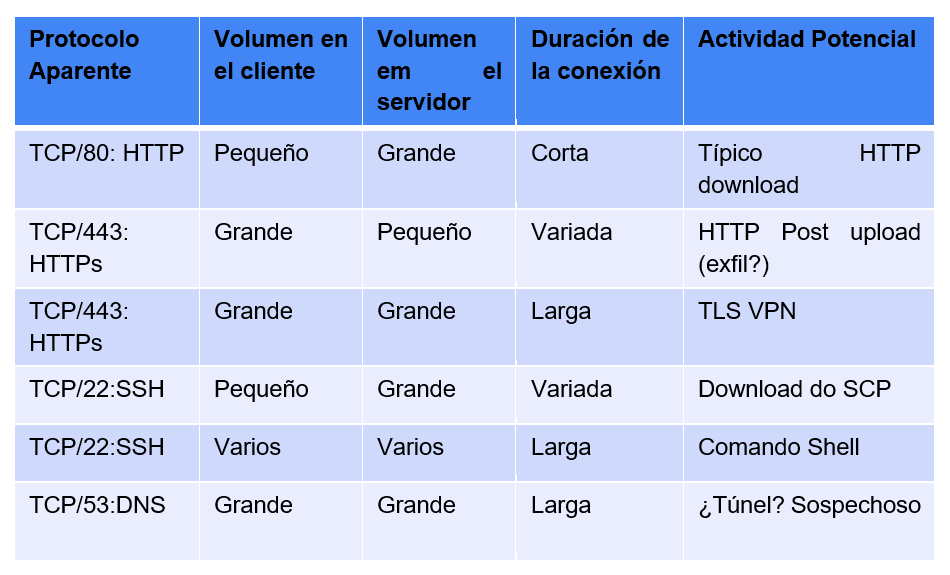
Asociando estos factores es posible crear líneas de base de monitorización para, a través de
las estadísticas puestas a disposición por los flujos, saber, por ejemplo, si una conexión
SSH (generalmente puerto 22/tcp) que dura demasiado poco, o si una conexión HTTP (puerto
80/tcp) que dura demasiado tiempo, son accesos legítimos o posibles ataques. La tabla
siguiente muestra ejemplos de observaciones que pueden hacerse asociando los factores
descritos.
Los datos de flujo también pueden ser una buena alternativa para el tráfico cifrado, cuando
la organización no dispone de inspección TLS/SSL: esto resulta útil porque, si no existe la
capacidad de inspeccionar el tráfico cifrado, una captura completa de este tipo de tráfico
se convierte en un enorme desperdicio de recursos, sobre todo si hablamos de almacenamiento.
Estrategias de captura
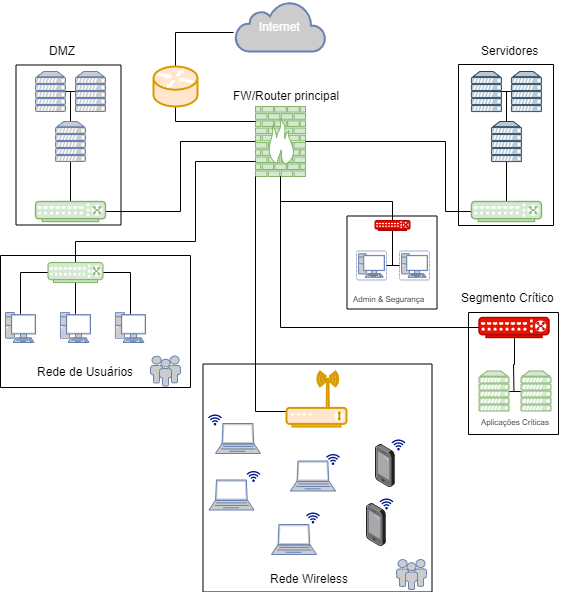
En el marco anterior, hay varios lugares donde se pueden recoger datos. Sinceramente,
cualquier punto de agregación de la red es un gran candidato para capturar los flujos
completos o sólo los flujos. Lo primero que hay que tener en cuenta es que existen distintos
niveles de criticidad y valor de los datos.
Comprendiendose, junto con los volúmenes de datos producidos en cada segmento, la
organización puede planificar una solución de captura.
Como sugerencia, los posibles puntos de agregación en el escenario anterior se diferencian
por colores.
• En color verde, puntos de exportación de flujos;
• En rojo, los puntos en los que puede ser necesaria la captura total,
• En Amarillo, puntos que contienen mucha información y son candidatos a
la exportación de flujos, pero con menor prioridad.
Si aún se encuentra en la fase de planificación de la captura de datos, o si tiene previsto
realizar una reestructuración del proyecto de captura en su infraestructura, los pasos
siguientes pueden dar una idea de lo que debe hacer.
1: Identificar los datos críticos
Captar todo el tráfico no es ni mucho menos una estrategia barata para la mayoría de las
organizaciones (si puede permitírselo, ¡siéntase un privilegiado!). El primer paso que
podemos dar es identificar cuáles son los datos más críticos de la organización para definir
la mejor estrategia de visibilidad de esos datos. Para esos datos y los activos que los
almacenan o en los que viajan, es probable que necesite una captura completa.
2: Conozca su red
Parece obvio, pero hay que decirlo: muchas organizaciones no tienen ni siquiera un
conocimiento de alto nivel de sus sistemas y equipos (por ejemplo, S.O. e IP de todos los
activos). Una buena estrategia podría ser empezar por trazar las rutas de los datos críticos
a Internet y a los sistemas de escritorio de los administradores que controlan esos datos.
3: Identificar cuellos de botella y puntos críticos de la red
Si conoce bien la red, podrá identificar los puntos en los que confluyen varias subredes o
VLAN y plantearse el nivel óptimo de captura de datos. A continuación, identifique las redes
críticas que operan switches y routers y verifique sus capacidades de captura. Estos
dispositivos están entre el usuario y los datos e Internet (si los sistemas pueden
conectarse a Internet).
4: Identificar los centros de gravedad críticos
Encontrar en el entorno lugares con altas concentraciones de un determinado objeto: ¡datos
críticos! Al definir estos centros, la organización reflexiona sobre lo que es realmente
importante en términos de protección. Sin embargo, los centros de gravedad críticos incluyen
cosas diferentes, según el tipo de empresa.
He aquí algunos ejemplos:
• Repositorios de código fuente (empresas de software)
• Sistemas contables (sector financiero y empresas que cotizan en bolsa)
• Sistemas de administradores de sistemas (suelen contener planos,
contraseñas, diagramas y software)
• Aplicaciones web desarrolladas internamente utilizando credenciales
(AD, LDAP)
• Servidores DNS
5: Planificar los exportadores de flujos y los puntos de captura total
En lugares con gran volumen de tráfico, como las pasarelas de Internet, es más interesante
captar los flujos de datos. En los cuellos de botella de datos críticos y en los
dispositivos de red críticos, puede ser interesante aplicar ambos enfoques: tanto los flujos
como la captura completa.
6: Verificar el cumplimiento de los requisitos
Los datos de flujo pueden ayudar a cumplir los requisitos de conformidad de los registros,
sin embargo es necesario comprobar con la norma si son suficientes y en qué puntos se pueden
utilizar estos metadatos para cumplir algún requisito.
Conclusión
A pesar de todas las ventajas, la captura de flujos no es una bala de plata y no resolverá
todos los problemas de supervisión de la organización, además de traer consigo algunos
inconvenientes, como:
• Se requieren análisis y asociaciones para averiguar los usuarios
implicados en ese tráfico para poder identificar a los equipos;
• Los NATs pueden hacer que la captura sea inconsistente, ya que el flujo
se registra en el exportador, por lo que es necesario tenerlo en cuenta a la hora de
configurarlo;
• No es posible ver el contenido de la comunicación a través de los
flujos.
En este sentido, siempre es importante equilibrar, variar los planteamientos y considerar
las distintas posibilidades para mejorar la seguridad y la gestión en general. Los datos de
flujo son uno más de los grandes aliados para la protección de las infraestructuras.
Terminando el razonamiento, los flujos son potentes para monitorizar cualquier red y
proporcionan una gran visibilidad de la infraestructura a bajo coste, precisamente porque la
mayoría de las organizaciones ya disponen de activos capaces de exportarlos, tanto en
entornos predominantemente on-premise como en entornos cloud o híbridos: proveedores como
AWS y GCP ponen los datos de flujo a disposición del cliente. A menudo, lo que falta es
simplemente habilitar la exportación de los flujos y apuntar a un colector/analizador. En
caso de que la organización no disponga de recopiladores/analizadores, crear un marco para
el análisis es relativamente sencillo y barato. Rara vez es necesario comprar hardware
adicional.