

Ideias, informações e conhecimentos compartilhados pela equipe
de Investigação, Desenvolvimento e Inovação da BASE4 Security..
Ideias, informações e conhecimentos compartilhados pela equipe
de Investigação, Desenvolvimento e Inovação da BASE4 Security.

SHARE
Automatizar a implementação de proxy com Python
Durante a execução de uma auditoria, ou noutros casos, tais como quando
consumimos um serviço, que pretendemos evitar o bloqueio de IP, ou no caso de correr uma web
crawling/spider, temos de encontrar uma forma de alterar o nosso verdadeiro IP a cada poucos
pedidos ou tempo. Existem diferentes formas de executar esta tarefa dentro de duas
categorias distintas, a forma de utilizar infra-estruturas gratuitas (tais como procuradores
públicos ou tor) e a outra utilizando um serviço privado de um procurador rotativo ou a
utilização do conhecido serviço da Amazon.
Neste caso, iremos analisar em pormenor como tirar partido das listas de procuradores
públicos, mas mencionaremos também os outros pontos acima mencionados.
Iremos desenvolver um código Python que facilitará a automatização de:
• Extracção e digestão de listas de procuradores públicos
• Desenvolvimento de código para filtrar proxies com base na latência e
outros critérios.
• Verificação automática de cada procurador
• Configuração automática de um equilibrador de carga com lista de proxy
verificada
• Geração de ficheiro de configuração de cadeias de procuração
(alternativa)
Fonte e digestão de informação
Antes de iniciarmos o desenvolvimento do primeiro projecto do código, precisamos de
encontrar uma fonte de informação para o nosso propósito. Vale a pena notar que se tornarmos
esta fase tão simplificada quanto possível, poderemos mais tarde acrescentar mais facilmente
novas fontes e prolongar a vida do código e a paciência do programador.
Após uma simples pesquisa no Google, encontramos um serviço interessante devido à forma
aberta de partilhar a lista de procurações (download em formato json, txt, csv,...). Isto é
a nosso favor, pois estaremos a poupar tempo ao não termos de analisar o HTML.
O serviço que utilizaremos será Genode (https://geonode.com/free-proxy-list/)
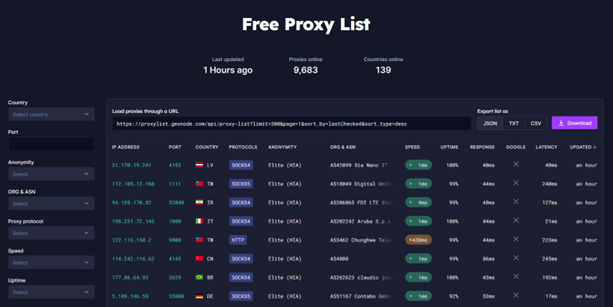
Vamos analisar como obtemos esta informação se a obtivermos com o curl e a processarmos com
jq, mas primeiro vamos modificar um pouco o URL, uma vez que o link fornecido pela página
trará 500 proxies, vamos trazer apenas um para examinar a resposta e a estrutura dos dados
recebidos:

A resposta é a seguinte:
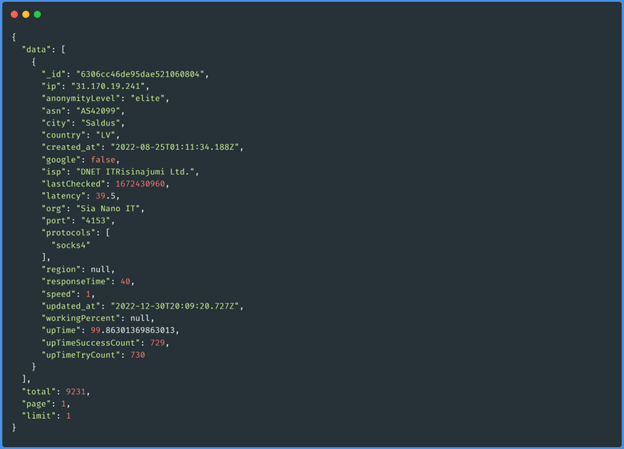
Podemos utilizar toda esta informação das formas mais criativas, para este caso só vamos
utilizar dados["ip"], dados["latência"] e total. O número total de procurações pode não ser
muito importante agora, mas será útil percorrer as diferentes páginas, tendo em mente que a
url mostra os resultados por página, e o número máximo de procurações a trazer é de 500. As
seguintes funções são simplificadas tanto quanto possível para compreender o fluxo de
informação, e foram removidos os fios desnecessários que tornam a leitura difícil:
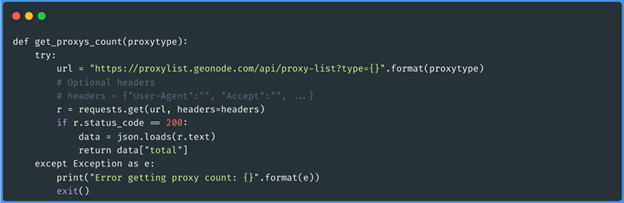
Função get_proxys_count(“socks5”)
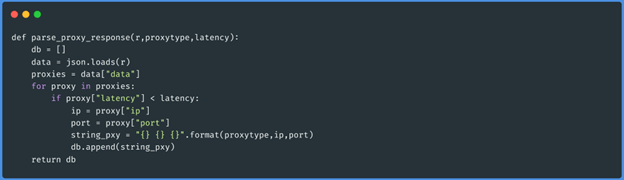
Função parse_proxy_response(json,”socks5”,50)
Função get_proxy_list(“socks5”,50)
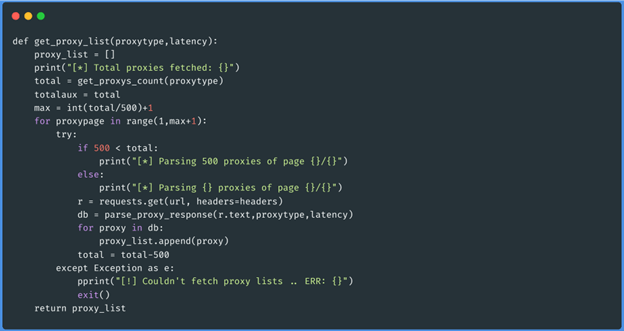
Estas três funções obtêm o json de cada página dos proxies do tipo que queremos (http,
https, meias4 e meias5), depois passa por esses dados e gera um array com os proxies que têm
menos latência do que 50 (passamos isto como parâmetro ao executar o script). Os dados serão
armazenados da seguinte forma:

Teste de procurações
Para esta fase, a próxima coisa a fazer é tomar como entrada o resultado da fase anterior,
onde já temos os nossos procuradores com o formato do ficheiro de configuração ProxyChains.
Uma das formas de testar estes proxies é fazer um pedido a uma página web através do
protocolo, ip e porta que obtivemos, e analisar a resposta. Com base nisto o nosso guião
identificará quais os proxies que podemos utilizar a partir da nossa localização, se
executarmos o guião a partir de diferentes países IP, obteremos resultados diferentes, uma
vez que alguns proxies só são activados para certas áreas.
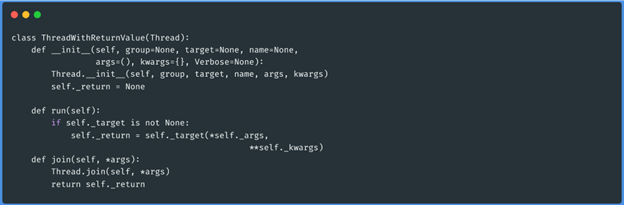
Ao utilizar o módulo de pedido se testarmos por exemplo 2.000 procuradores, isto será
bastante lento se for feito um de cada vez. Para tal, vamos utilizar a biblioteca de
enfiamento Python, com a biblioteca de enfiamento Python. Uma vez que a execução do teste
precisa de devolver um valor positivo ou negativo no caso de o procurador ser utilizável,
precisamos de declarar uma nova classe, a biblioteca em questão.
Classe de rosca com valor de retorno
Now we can run the function that will check the proxies and determine based on the returned
value if the proxy is alive or not. The function is as follows:
Function check_proxy(“socks5 1.1.1.1 3128”,”http://ifconfig.me/ip”)
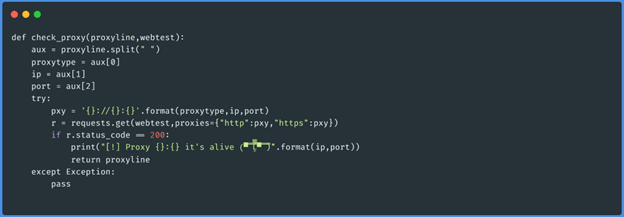
Podemos agora executar a função que irá verificar os procuradores e determinar com base no
valor devolvido se o procurador está vivo ou não. A função é a seguinte:
Function do_multi_thread_check(array_proxies,”http://ifconfig.me/ip”):
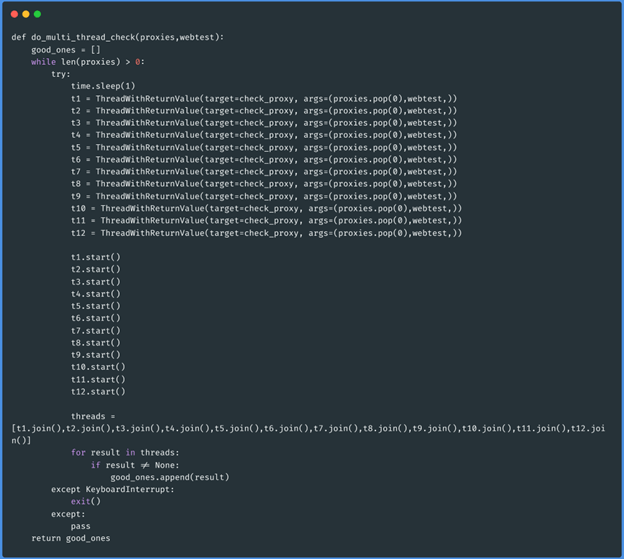
Esta função específica receberá como parâmetro a lista de procurações filtradas por latência
e o website contra o qual queremos testar se funcionam.
A lógica de programação desta última função será que, enquanto houver proxies no argumento
dos proxies, serão criados 12 trabalhadores, cada um extraindo um proxy e removendo o valor
extraído da lista original até que o argumento esteja vazio. Se o procurador estiver vivo, o
trabalhador que o verificou devolve a informação, e esta é armazenada numa nova variável
chamada good_ones. No final da tarefa, a função devolve estes procuradores de
trabalho.
Equilibrador de carga
A fase anterior deixou-nos com uma variável com proxies testados e funcionais. A tarefa
agora é levantar um único porto com um serviço que possa distribuir a carga do tráfego que
pretendemos "proxy". Uma boa alternativa para realizar esta tarefa, é o seguinte projecto
que se adapta às nossas necessidades: https://github.com/extremecoders-re/go-dispatch-proxy
Esta ferramenta é uma adaptação da expedição-proxy desenvolvida em NodeJS e Golang. Este
último detalhe parece interessante, uma vez que é uma linguagem muito rápida. Para utilizar
a ferramenta, precisamos de instalar a libpcap-dev:

Podemos compilar o projecto ou descarregar a versão funcional. No nosso caso, iremos
compilar o código na nossa máquina

E é tudo! Agora temos o binário equilibrador de carga compilado, se tudo correu bem, devemos
obter como saída no último comando uma mensagem como a seguinte:

O passo seguinte será mover o binário de equilibrador de carga para a pasta onde
desenvolvemos o guião Python, depois disso, desenvolveremos a seguinte função para levantar
o binário compilado com os bons proxies que obtivemos no passo anterior:
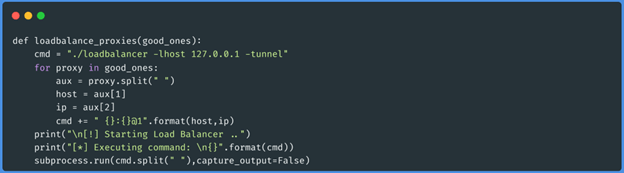
Esta função irá montar o comando de acordo com a documentação do repositório e executá-lo
através do subprocesso.run.
Vamos executar o código desenvolvido com os seguintes argumentos:

A execução do nosso guião produz a seguinte produção:
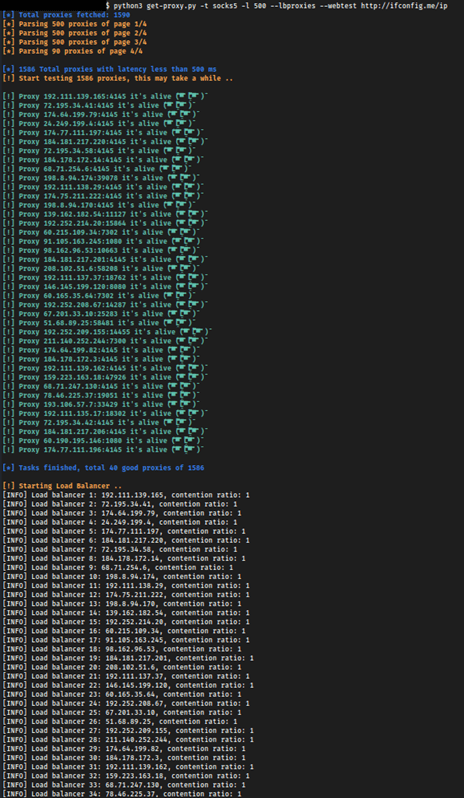
Temos agora um equilibrador de carga a funcionar com procuradores públicos, mas tenha
cuidado ao utilizar estes procuradores, pois geralmente registam todo o tráfego enviado,
incluindo cookies de sessão, credenciais ou informação sensível que pode ser comprometida.
Elevando a ligação através do protocolo Socks5 , o serviço pode ser utilizado para
digitalizar portas.
Este balancim só funciona com meias5 proxies, pelo que o nosso código deve ter a validação
correspondente para não levantar proxies de outros tipos (e assim desperdiçar tempo
valioso).
Para realizar um scan de porta, necessitará de um scanner que tenha suporte para meias5
proxy, tal como naabu (https://github.com/projectdiscovery/naabu). Basta passar o scanner
pela porta do equilibrador de carga, que está definida para 8080 por defeito.
Geração de proxychains.conf
Analisando até agora, analisámos as listas de procuração, processámo-las, testámos o estado
de cada uma e construímos um equilibrador de carga com as activas, tudo de forma
automatizada. Poderíamos acrescentar mais uma funcionalidade ao nosso script, na qual
geramos um ficheiro de configuração de cadeias de procuração. A seguinte função fará o
trabalho:
Função print_proxy_chains_file(array_of_active_proxies,1):
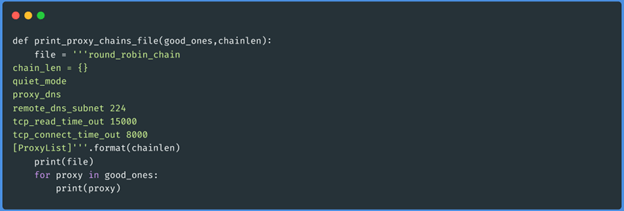
Vamos executar o nosso script para que, em vez de levantar um equilibrador de carga, imprima
o ficheiro de configuração das cadeias proxy, desta vez vamos baixar a latência para não
testarmos tantos proxies e usar a saída como um exemplo rápido. Também testaremos a partir
de um vps as ligações de entrada dos procuradores para verificar de onde as obtemos:
No localhost:

No the VPS:

A produção sobre o localhost, dá o seguinte resultado:
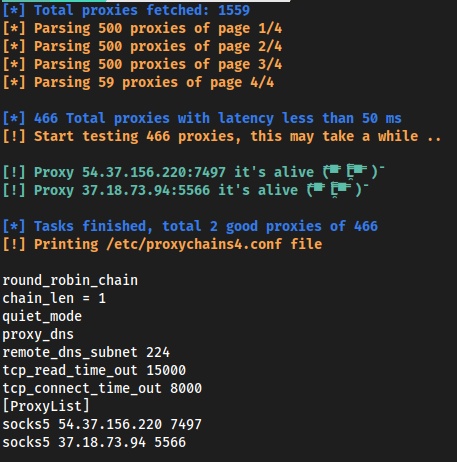
Enquanto no lado do VPS obtemos o seguinte resultado:

Para utilizar os proxies que obtivemos, só precisamos de copiar a saída do guião para o
ficheiro proxychains.conf:

Conclusão
Desta forma, podemos automatizar a tarefa de verificar uma lista de procuradores e
utilizá-los com cadeias de procuradores ou levantando o nosso próprio equilibrador de carga.
Como descrito na introdução, existem outras formas de executar esta tarefa, por exemplo,
utilizando o projecto de doca rotativa-tor-http-proxy podemos elevar um HAProxy sobre o
protocolo HTTP que tem a mesma funcionalidade que o código que desenvolvemos mas utilizando
múltiplas instâncias de tor, que são actualizadas de tempos a tempos.
Além disso, existe outra alternativa que utiliza os serviços API Gateway da Amazon, este
método é muito rápido quando queremos realizar fuzzing na web e escapar aos controlos de
bloqueio de IP. Estes últimos métodos mencionados não são compatíveis com um scan de porta,
uma vez que o protocolo utilizado é HTTP e para este cenário a única forma possível é o
guião desenvolvido neste texto.
O repositório GitHub, onde se encontra todo o código desenvolvido da ferramenta, está
abaixo: https://github.com/BASE4-offensive-operations/autolb-proxies